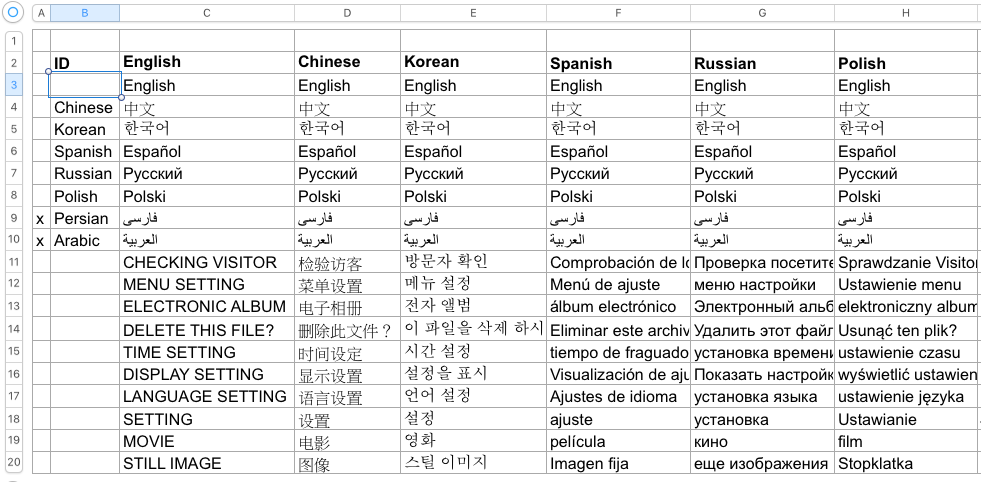
開發 Embedded Systems 相關應用時,常得處理多國語言。而系統資源受限的的場合,就算掛了 OS,往往也沒內建多國語言。這時候只能捲起袖子自己處理了。自幹的過程,很直覺地,多數人都會想到要有個類似右圖這樣的 Excel 字典檔當作翻譯表。
有了翻譯表後,我們還要有個字庫(font)。為了存取字庫裡的字,我們要先決定字序(character order)。有了字序後,我們就能根據字序,把翻譯表裡面的多國語言訊息,一一轉換成字序的串列(a sequence of character orders)。要秀某個訊息時,就根據這個字序列,回過頭把字庫裡的字形(glyph)抽取出來顯示。
typedef enum {
SEASON_BEGIN,
SPRING = SEASON_BEGIN,
SUMMER,
AUTUMN,
WINTER,
SEASON_END,
SEASON_TOTALS = SEASON_END // the total number of seasons
} Season;





























{kind=link}
{kind=link}
{kind=link}
{kind=link}