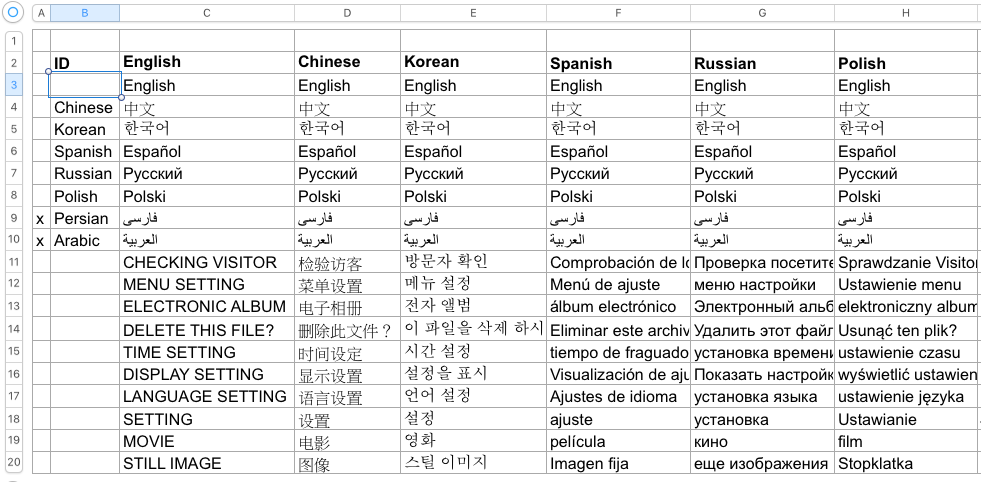
開發 Embedded Systems 相關應用時,常得處理多國語言。而系統資源受限的的場合,就算掛了 OS,往往也沒內建多國語言。這時候只能捲起袖子自己處理了。自幹的過程,很直覺地,多數人都會想到要有個類似右圖這樣的 Excel 字典檔當作翻譯表。
有了翻譯表後,我們還要有個字庫(font)。為了存取字庫裡的字,我們要先決定字序(character order)。有了字序後,我們就能根據字序,把翻譯表裡面的多國語言訊息,一一轉換成字序的串列(a sequence of character orders)。要秀某個訊息時,就根據這個字序列,回過頭把字庫裡的字形(glyph)抽取出來顯示。
如果要通吃幾乎各國的語言,一個奢侈的做法是直接用 Unicode 當字序,建立完整的字庫。不過這不適合用在資源受限的場合。
多年前,我遇到決定字序的問題時,想了一種簡單又好用的表示法。以 ASCII code 有對應字形的部分為例子,可以利用這個表示法描述如下:
# Printable characters of ASCII code
:0x20
!"#$%&'()*+,-./0123456789:;<=>?
@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_
`abcdefghijklmnopqrstuvwxyz{|}~
- 以 # 開頭的行表示該行是註解。
- :0x20這行,代表接下來的字元從 0x20 (有可以寫成十進位的 32)開始編號。
- 行尾的空白字元會被忽略掉。
- 這整段看起來很直覺,就是列出了 ASCII code 32 到 127 間的字元。
因為英文太常用了,所以 32 到 127 這段通常會保留給 ASCII code 用。其他國家的語言,我們可以只列出有用到的,以節省字庫佔的儲存空間,以下是實際的例子:
# A sample character list file
:0x20
!"#$%&'()*+,-./0123456789:;<=>?
@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_
`abcdefghijklmnopqrstuvwxyz{|}~
:0xA0
áíñóúąćęśП
РУЭабвдежз
ийклмнопрс
туфщыьэюя中
件像册删单图子定客影
文时显检此电相示置菜
言设访语间除验간겠국
까뉴니메문미방범삭설
스습시앨어언영을이인
일자전정제지틸파표하
한화확?
有了翻譯表(dic.xls)跟字序表(char.lst)後,就可以利用 LangConvert 產生下述的幾個 C 原始程式:
- LangID.h: Language ID 的 enum 。
- MsgID.h: Message ID 的 enum。
- mlang.i: 將每個訊息的多個語言版本,一一列出對應的字序串列
接下來還缺個從字序表轉出字形(glyph)的工具,這個大家可以自己練習看看。我這裡著重在介紹領域專用語言來表達字序表。
LangConvert 還有個新增的 command 可以透過 Google Translate 來對空的字典檔實施自動翻譯,有興趣的可以直接執行 demo_trans.bat 觀察看看。它會吃進還沒翻譯好的 dic_empty.xls ,然後吐出翻譯好的 dic_trans.xls 。





0 comments:
Post a Comment